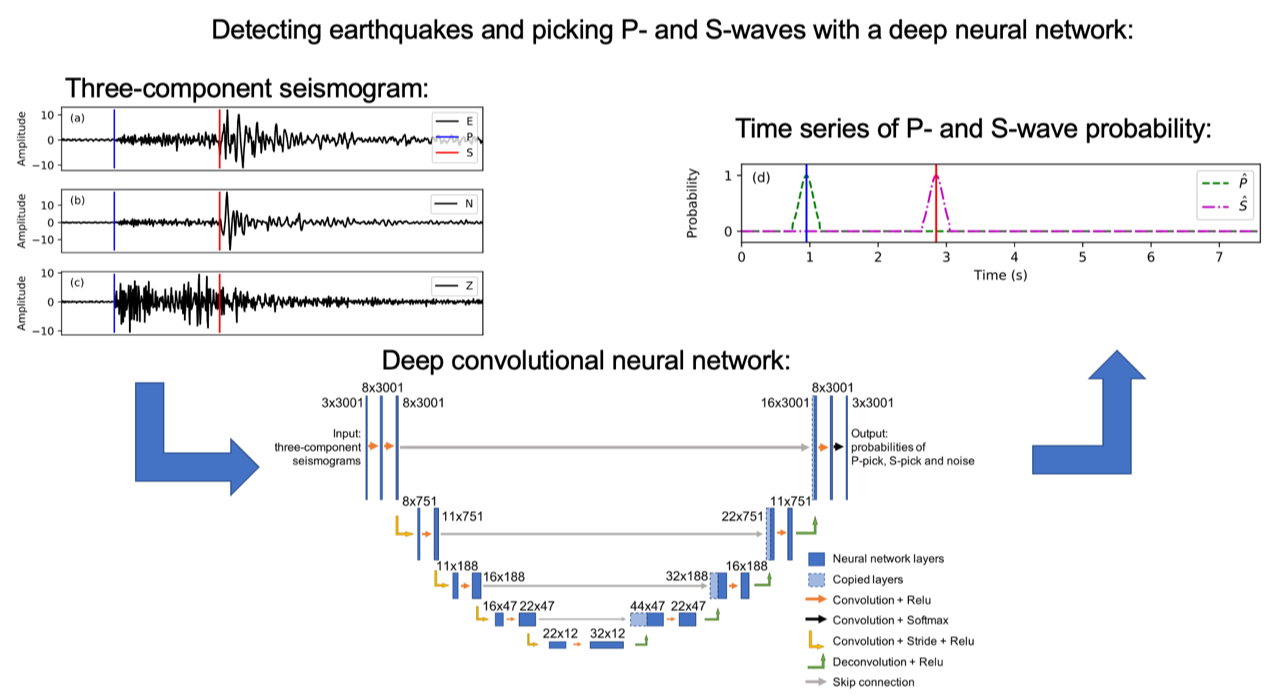
Observations of earthquakes are essential to fully characterize and understand Earth’s geodynamics and the seismic hazard they present. Because large damaging earthquakes are rare, it is difficult to anticipate future seismic damage. However, smaller earthquakes occur frequently and can be used to delineate unknown fault structures and to indicate the state of stress of a particular fault. This motivates the creation of earthquake catalogs that capture as small of signals as possible. Earthquake detection techniques refined in the last decade, including template matching1 and neural networks2, have shown great promise as tools for accurate earthquake catalog creation. However, these techniques are computationally costly. To this end, we work to build a documented example that shows how to containerize locally-developed codes that parallelize template matching- and neural network-based earthquake detection methods for use in the commercial cloud.
What is the role of computation in addressing the problem, and what is the nature of the computational approach?
Because earthquake detection is performed on seismic time series, codes that perform earthquake detection can easily be parallelized over days, weeks, etc. The commercial cloud is ideal for expanding these processes because it provides unlimited access to vCPUs and flexible options for scaling.
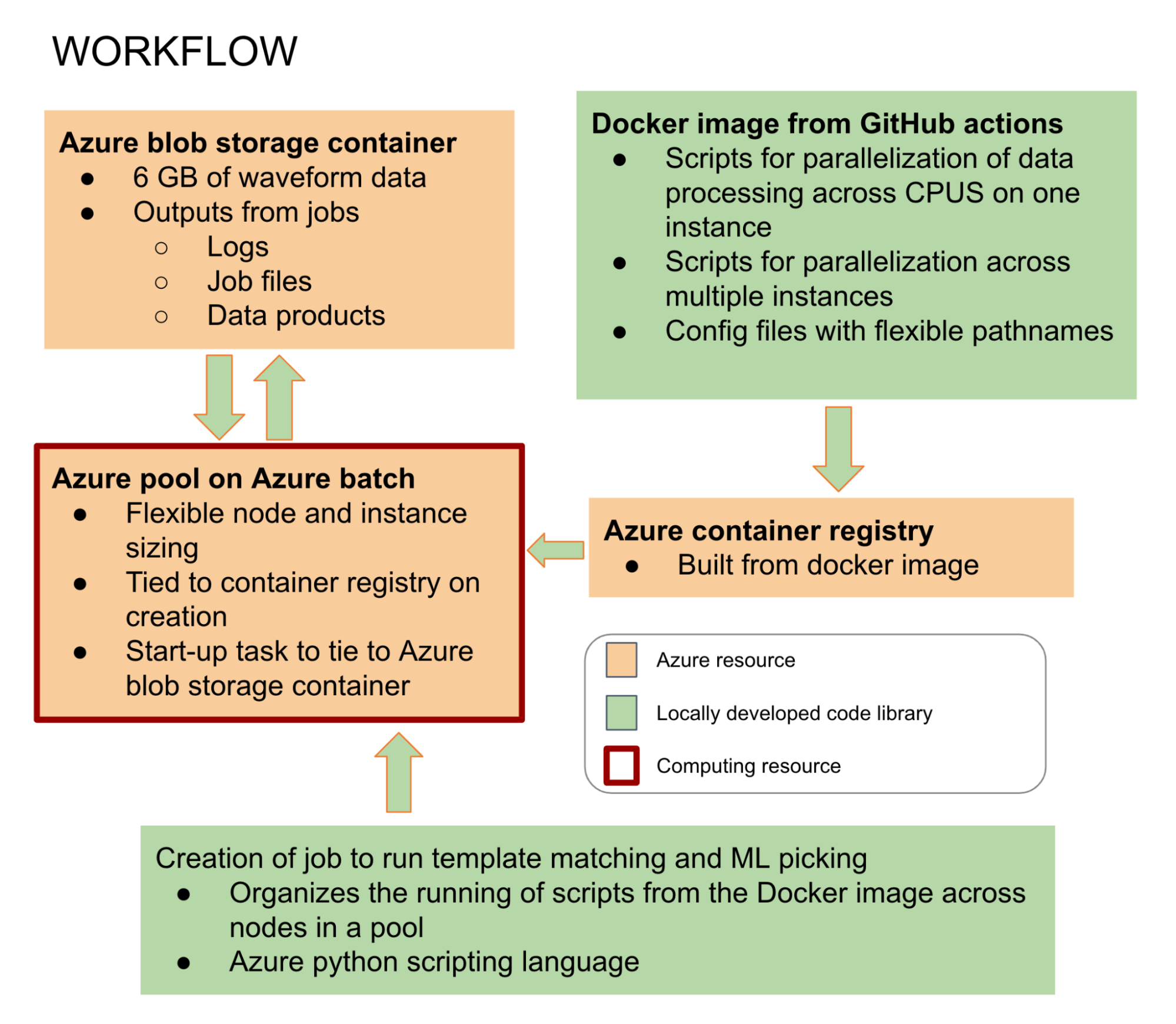
We constructed our code base to parallelize both template matching- and neural network-based earthquake detection by evenly distributing one day of earthquake detection at a time across as many CPUs as available. We convert this code to a Docker image using GitHub actions. After the code is containerized, we host it on Azure services using a container registry. We also store seismic time series, which is our raw data, within an Azure storage container. After constructing these resources, we create a pool of virtual machines using Azure batch. We start up each virtual machine in the pool with our container downloaded and storage container mounted. We can then remotely assign tasks to the pool to run scripts within the container on each virtual machine. The scripts automatically parallelize the processing both across the pool and across CPUs within each virtual machine.
This resource set-up is shown below:
How did using cloud services advance your research?
Azure cloud services have expedited our analysis by providing access to on-demand machines that exceed the capabilities of our lab servers, which can get crowded at times. These services could be a game-changer for those without access to large servers who only need computational resources for a limited amount of time. We hope that the documented example we are building will be useful to researchers in those situations.
What was your experience with the technical side of working in the cloud?
We made extensive use of Azure Container Instances, Azure Files, and Azure Batch. We were particularly interested in services for reproducible scientific analysis that are transferable across Cloud providers (for example ACI or Batch which allows running Docker containers). We were particularly happy with Azure Files having the ability to create mountable drives on MacOS and Linux machines that worked on local lab servers as well as Cloud instances.
We note that the learning curve to configure a set of Azure resources that fit our needs proved significant. Many Azure resources are set up in a non-intuitive way and require extensive layers of specific permissions settings in order for various resources to work in tandem. This can be difficult for an individual researcher to navigate.
Related references:
- Our initial experience with the cloud and earthquake detection workflows came from the eScience Institute's Winter 2022 incubator program. The project summary can be found here: https://escience.washington.edu/winter-2022-incubator-projects/
- The terraform scripts and documentation for Azure infrastructure configurations developed during the incubator are held here: https://github.com/Denolle-Lab/azure
- The in-progress code base for the work described here can be found at this GitHub: https://github.com/Denolle-Lab/seismicloud
Authors:
Marine Denolle, Assistant Professor, Earth and Space Sciences, University of Washington
Scott Henderson, Research Scientist, Earth and Space Sciences, University of Washington
Zoe Krauss, PhD Candidate, Oceanography, University of Washington
Yiyu Ni, PhD Student, Earth and Space Sciences, University of Washington
Literature references:
1 Chamberlain, Calum J., et al. "EQcorrscan: Repeating and near‐repeating earthquake detection and analysis in Python." Seismological Research Letters 89.1 (2018): 173-181.
2 Zhu, Weiqiang, and Gregory C. Beroza. "PhaseNet: a deep-neural-network-based seismic arrival-time picking method." Geophysical Journal International 216.1 (2019): 261-273.
